Architecture¶
Cherimoya is a compact convolutional architecture for predicting genomic modalities from DNA sequence. It builds on the ConvNeXt design philosophy, adapting it to the challenges of noisy high-throughput genomics experiments.
Model Overview¶
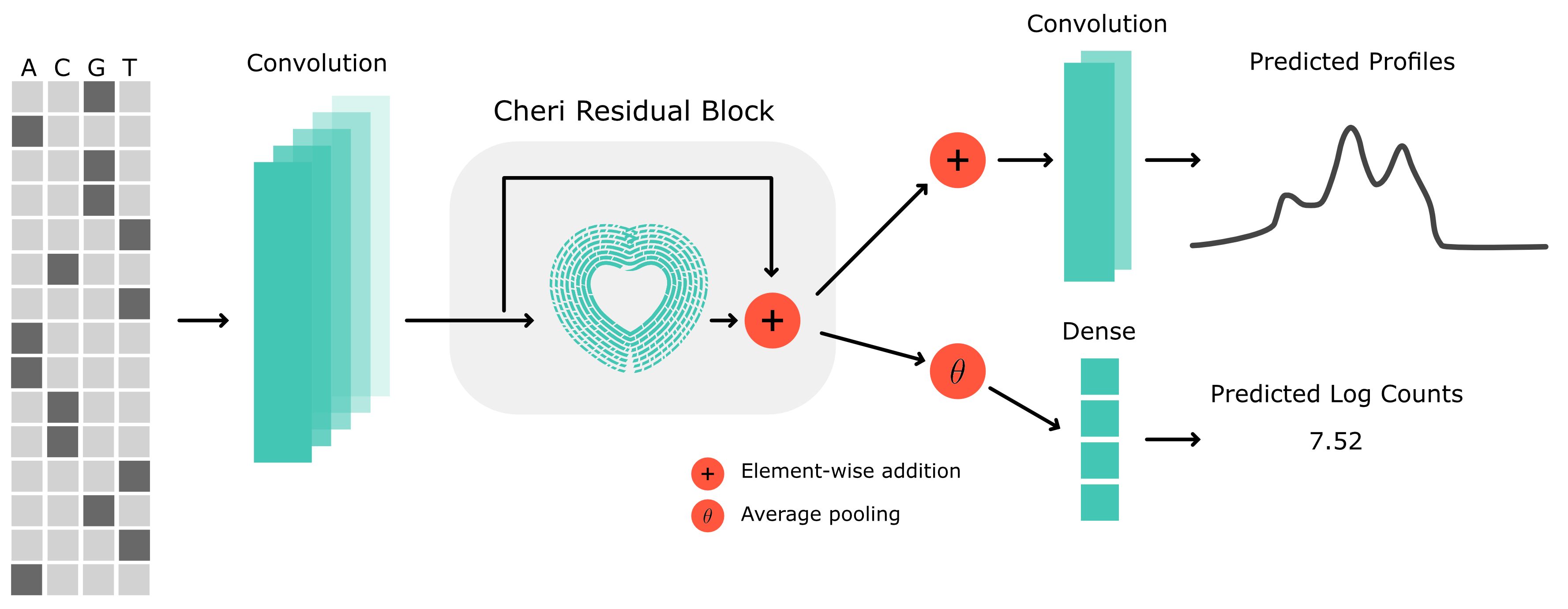
The model consists of three stages:
Input convolution: A 1D convolution (kernel size 21) maps the one-hot encoded DNA sequence (4 channels) into a higher-dimensional feature space.
Cheri Blocks: A stack of blocks with exponentially increasing dilation rates (1, 2, 4, 8, …) that progressively expand the receptive field. The default configuration uses 9 blocks with 96 filters.
Output heads: Separate heads for profile prediction (a 1×1 pointwise convolution) and count prediction (a linear layer over the mean-pooled features).
The Cheri Block¶
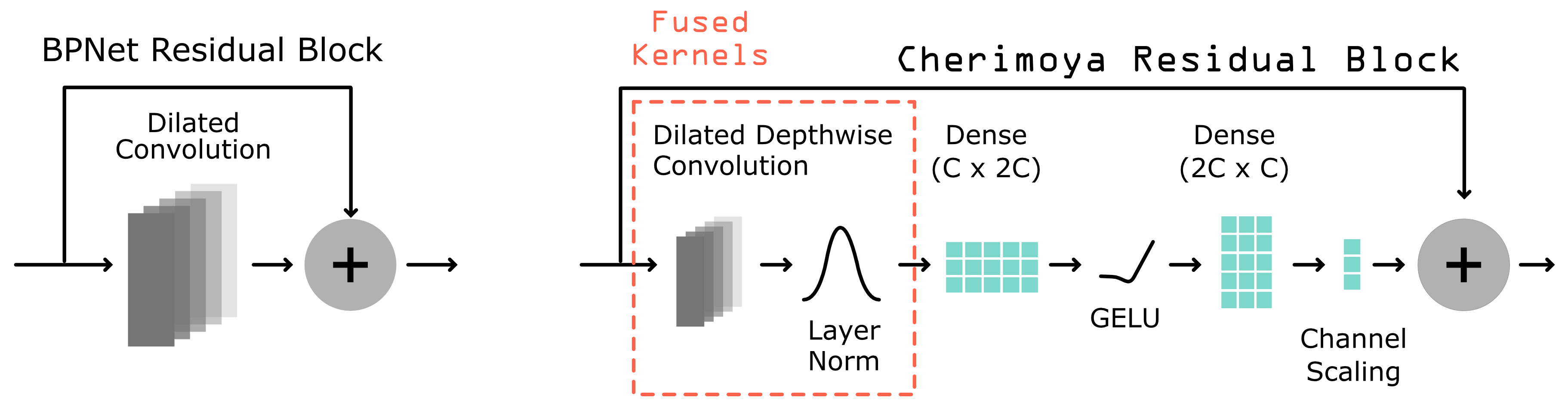
Each Cheri Block performs the following operations:
Dilated depthwise convolution — aggregates spatial information independently for each channel, with a kernel size of 3 and increasing dilation rates.
Layer normalization — stabilizes activations. The convolution and normalization are fused into a single custom Triton GPU kernel for efficiency.
Expansion projection — a linear layer projects from
n_filterstoexpansion × n_filtersdimensions, whereexpansionis configurable on bothCheriBlockandCherimoya. Default is 2.GELU activation — the approximate
tanh-based variant.Contraction projection — projects from
expansion × n_filtersback ton_filtersdimensions.Residual connection with fixed scaling — the MLP output is scaled by a configurable fixed constant (
residual_scale, default0.15) before being added back to the input. The small constant keeps the residual path near-identity at initialization, which stabilizes training of deep stacks. BothCheriBlockandCherimoyaacceptresidual_scaleas a constructor argument.
In code:
def forward(self, X):
X_conv = fused_dilated_conv_norm(X, self.conv_weight, self.dilation)
X_mlp = self.linear2(self.activation(self.linear1(X_conv)))
return X + X_mlp * self.residual_scale
Custom Triton Kernel¶
The dilated depthwise convolution and layer normalization are fused into a
custom Triton kernel (FusedDilatedConvNormFunc) with both forward and
backward passes. This fusion eliminates intermediate memory allocations and
achieves ~2–3× speedup over the native PyTorch implementation.
The kernel is autotuned across:
Number of warps: 4, 8, 16
Number of pipeline stages: 2, 3, 4, 5
Block sizes: 32, 64, 128, 256
CPU and Triton-less fallback¶
When a tensor is on the CPU, or when Triton is not installed, the block
falls back to a pure-PyTorch implementation
(cherimoya.cheri._cheri_conv_norm_cpu) that produces numerically
equivalent output up to floating-point error. The dispatcher
(fused_dilated_conv_norm) chooses between the two paths automatically
based on the input device. This means models can be constructed and run
on machines without a GPU, which is useful for debugging, testing, and
unit tests.
Loss Function Design¶
Cherimoya uses a two-component loss:
Profile loss: Multinomial negative log-likelihood (MNLL) over the base-pair resolution profile predictions.
Count loss: Mean squared error in log-space (
log1pMSE) between predicted and observed total counts.
These are combined using learned weighting parameters (lw0, lw1)
rather than fixed hyperparameters:
w0 = 1.0 / (2.0 * self.lw0 ** 2)
w1 = 1.0 / (2.0 * self.lw1 ** 2)
loss = w0 * profile_loss + w1 * count_loss
The weights are automatically frozen once their gradients become negligible, preventing further unnecessary updates.
Training Strategy¶
Cherimoya uses a dual-optimizer approach:
Muon optimizer for 2D projection weights (the
linear1andlinear2layers in each Cheri Block)AdamW optimizer for all other parameters (convolutions, biases, loss-weight scalars)
Both optimizers use a warmup + cosine decay learning rate schedule:
5 epochs of linear warmup (from 1% of the target learning rate)
Cosine annealing to
1e-5over the remaining epochs